
As we keep data for longer and try harder to share and re-use data, it becomes critical that data is accurately catalogued and easily retrievable.
Object Storage is a way of storing huge numbers of files without having to worry about where they live or manage a folder-based file system. Object stores can be distributed globally over many sites. This ensures data remains available even during major site failures, and can allow faster access to data from remote locations.
At OCF we work with many object storage vendors. Although long touted as the saviour to the scalability crisis being waged on file systems, object storage still remains niche outside of web-scale deployments.
When you’re going for site-level resiliency, object stores start to become unbeatable.
Team work
An object store needs to be a repository or means of sharing data. We shouldn’t try to replace file storage with objects, rather use the strengths of each together to achieve more.
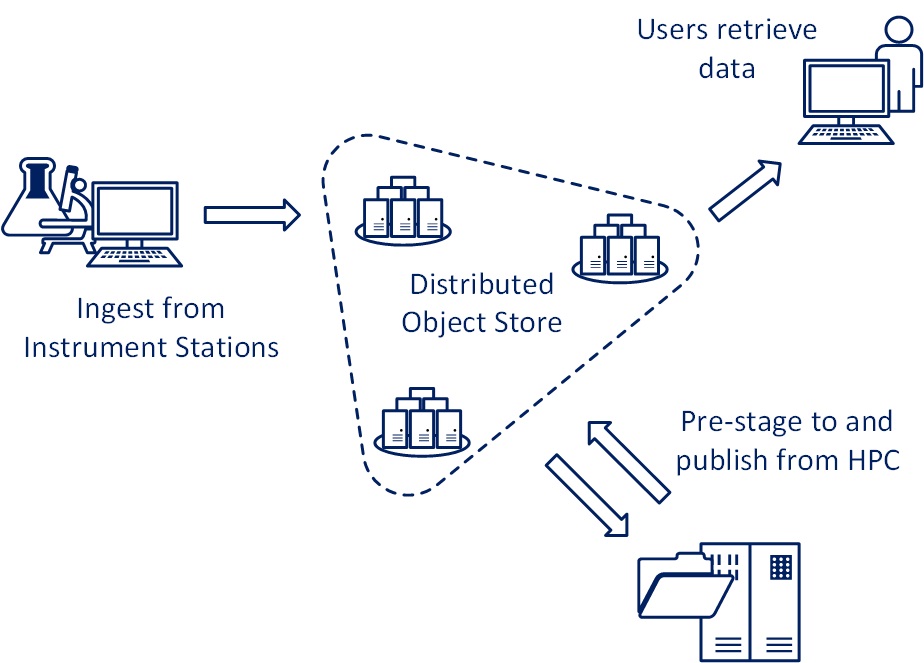
In HPC land, much of the largest data sets are generated by scientific instruments like high resolution microscopes, spectrometers and sequencers.
In an object based workflow, files generated by these instruments can immediately be objectised, tagged with appropriate metadata like researcher, project, instrument settings, what was sampled, and conditions which the data should be shared (example as required by some funding bodies). The resulting objects are then ingested into an object store for preservation.
If a researcher needs to re-visit the output they can do, and they can easily cache whole projects on their local systems.
With data catalogued in an object storage solutions’ metadata management system, it can be published and shared, giving researchers wanting more data, but without the extra funding, the ability to query past projects for similar instruments and samples.
Integrate with HPC
Although object stores tend to be too slow to efficiently support HPC resources, the programmatical nature of object interfaces allows them to integrate well into HPC workflows.
A HPC system usually consists of a cluster of compute servers with a shared high-speed file system known as scratch storage. Scheduling programs like SLURM are used to schedule and start compute jobs on the compute servers.
Similarly, any output written to the HPC’s scratch file storage can be assembled into an object and published to the object store after the job finishes.
Fuelling AI
A growing number of our life science customers are adopting AI and an object-based workflow. For AI, you typically need a lot of data, often more than one practitioner can generate.
The ability to pull many thousands of output files, tagged with what was sampled and observed from potentially hundreds of projects would be a treasure trove to AI researchers wanting to expand their dataset.
Although I do not foresee object storage replacing file storage for active research data, they do offer an excellent means to curate and preserve data to support research computing systems.
For more information please contact us here